
Zookeeper 是什么
Zookeeper 是一个分布式的协调服务,可以实现
- 统一配置管理。比如现在有A.yml,B.yml,C.yml配置文件,里面有一些公共的配置。将这些公共配置信息放到ZK中,修改ZK的信息,会通知A,B,C配置文件。
- 统一命名服务。节点存储ip地址,只需要访问Znode节点就可以获取这些ip地址。
- 统一集群管理。Kafka 的集群管理基于Zookeeper。
- 统一服务管理。Dubbo 的服务发现基于Zookeeper。
- 分布式锁。通过在持久节点下建立临时顺序节点,可以保证锁的有序,监听机制保障锁传递的高效。
原理
文件系统
数据结构
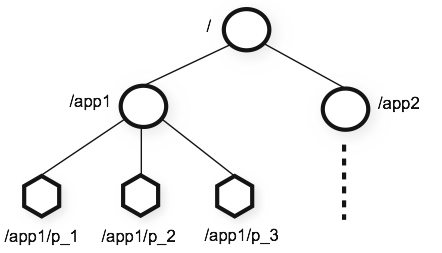
文件系统类似的,整体上可以看成一棵树,每个节点称作一个 ZNode,每个 ZNode 都可以通过其路径得到唯一标识。默认只能最多存储 1MB 的数据
但与文件系统不同,每一个 ZNode 节点都可以存储数据,但文件系统的目录不可以存储数据。
ZNode 类型
三大类:
- 持久节点,除非客户端主动执行删除操作,否则 ZooKeeper 不会删除持久的 znode
- 临时节点,客户端断开连接后,ZooKeeper会自动删除临时节点
- 顺序节点,每次创建顺序节点时,ZooKeeper都会在路径后面自动添加上10位的数字,从1开始,最大是2147483647 (2^32-1)
四种形式:
- 持久节点
- 持久顺序节点
- 临时节点
- 临时顺序节点
唯一事务id
每次的变化都会产生一个集群全局的唯一的事务id, Zxid(ZooKeeper Transaction Id),由Zookeeper的 Leader 实例维护。变化包括
- 任何的客户端连接到Server
- 任何的客户端断开与Server连接
- 任何的Znode节点被创建create、修改set、删除delete
通知机制(监听机制)
具体是基于观察者模式实现的。在ZooKeeper中,客户端是观察者,服务端是被观察者。 客户端通过注册Watch来监听服务端节点的数据变化。
ZooKeeper 的观察机制允许用户在指定节点上针对感兴趣的事件注册监听,当事件发生时,监听器会被触发,并将事件信息推送到客户端。
监听两方面的内容:
- 监听 Znode 的数据变化
- 监听子节点的数量变化
角色
一主多从的结构
- Leader,同一时间只会有一个Leader,负责发起和提交写请求。接收到写请求后同时发送给Follower,统计Follower写入成功的数量,超过一半则认为成功。
- Follower,处理读请求,Leader宕机后使用 Paxos 一致性算法的 Zab 协议负责选举新的Leader。
- Observer,处理读请求,但没有选举权
会话(Session)

client与ZooKeeper集群中的某一台server保持连接,发送读/写请求,读请求直接由当前连接的server处理,写请求由于是事务请求,由当前server转发给leader进行处理。同时,client还能接收来自server端的watcher通知。所有的这些交互,都是基于client和ZooKeeper的server之间的TCP长连接,也称之为Session会话。有了会话之后,后续的请求发送,回应,心跳检测等机制都是基于会话来实现的。
ZAB 算法与 Raft 算法的选举过程
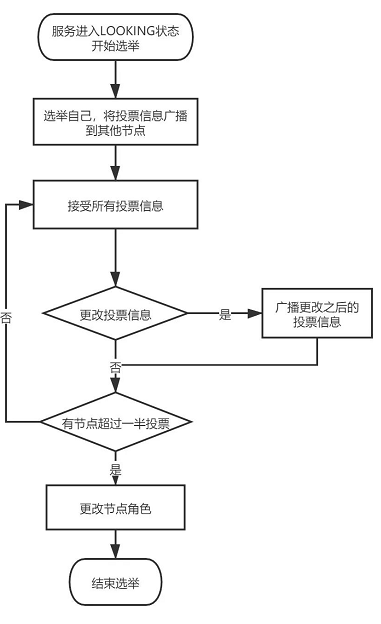
ZAB 算法
- 所有节点第一票先选举自己当leader,将投票信息广播出去;
- 按照规则(epoch 是否比自己的 epoch 大,以及 counter 是否比自己的 counter 大,总之选择zxid最大的投票信息,说明该节点的数据最全)判断是否需要更改投票信息,将更改后的投票信息再次广播出去;
- 判断是否有超过一半的投票选举同一个节点,如果是选举结束根据投票结果设置自己的服务状态,选举结束,否则继续进入投票流程。
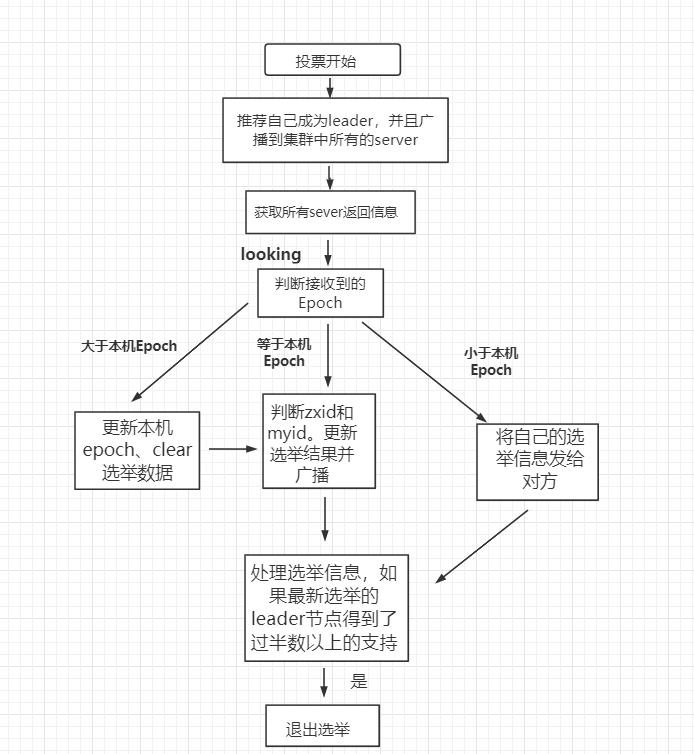
Raft
每个节点都有一个定时器,最先结束倒计时的节点最先发送选举的信号(基本也会是被选举为 leader)