
Elasticsearch是基于 Lucene 架构实现的分布式、海量数据的存储分析引擎,其中 Lucene 最主要的倒排索引结构,赋予了ES全文检索、模糊匹配、联合索引查询等等快速检索文档数据的能力,使得ES在这些查询的应用场景下优于数据库。适合用于搜索,不适合复杂的关系查询
倒排索引:简单理解为建立关键词和文档之间的映射关系,从关键词中找出所属的文档。普通搜索则是从文档中找关键词。
写数据的过程
- 客户端选择一个 node 发送请求,这个 node 就成为了 coordinate node (协调节点)
- 该协调节点将输入的 document 做哈希路由得到 shard id,将请求转发给 shard id 对应的 node
- 该 node 在 primary shard 上处理请求,并将数据同步到 replica 上
- 协调节点在写入完成后返回响应结果
读数据的过程
- 客户端选择一个 node 发送请求,这个 node 就成为了 coordinate node (协调节点)
- 该协调节点对输入的 document id 做哈希得到 shard id,将请求转发给 shard id 对应的 node
- 该 node 使用 round-robin 轮询算法在 primary 和所有 replica 中选择一个,让读请求负载均衡
- 协调节点返回查询结果
更新、删除数据的过程
本质上都是写操作!磁盘上的每个段都有一个相应的 .del 文件。
- 删除操作(不是删除索引)是逻辑删除,document 被标记为 deleted 状态。当段合并时,在
.del文件中被标记为删除的文档将不会被写入新段。 - 更新操作是把原 document 标记为删除,再写入新的 document 数据
为什么近实时
数据写入原理
大概分为三个步骤:write -> refresh -> flush
1、write:文档数据到内存缓存,并存到 translog
2、refresh:内存缓存中的文档数据,到文件缓存中的 segment 。此时可以被搜到。
3、flush: 缓存中的 segment 文档数据写入到磁盘
当数据添加到索引后并不能马上被查询到,等到索引刷新后才会被查询到。refresh_interval 参数设置为正数之后,需要等一段时间后才可以在es索引中搜索到,因为已经从内存缓存刷新到文件缓存中了。详见数据写入与查询存在时间差问题

- indexing Buffer 属于 ES 内存的一部分,OS 系统文件缓存属于操作系统的,不属于 ES 内存
- refresh 操作:定时将 ES 缓冲区转换成 segment 并写入系统文件的过程。(近实时搜索的根本原因)
- translog 日志文件,不管是 ES 缓冲区还是系统缓冲区的内容,只要没写入到磁盘,就会在日志文件里记录,当 flush 到磁盘后,内存和磁盘中的文件就会清空。日志文件也是先写入 os cache,默认每隔 5 秒刷一次到磁盘,所以可能存在5秒的数据丢失
- flush 操作:将 segment 持久化到磁盘,同时清理 translog。主要分为以下几步:
- 内存中的数据写入新的segment并放入缓存(清空内存区)
- 将commit point 写入磁盘,表示哪些 segment 已经写入磁盘
- 将 segment 写入磁盘,使用 fsync 命令
- 清空 translog 日志内容
为什么这么快
- 分布式储存:采用分布式储存技术,将数据存储于多节点,分散负载,优化整体执行效能。
- 索引分片:将每索引分裂为多片段,实现并行查询,提升搜索速度。
- 倒排索引:支持倒排索引数据结构,映射文档中每个词汇至文档出现位置,当搜索请求发生时,能快速检索包含所有搜索词的文档,迅速返回结果。
- 索引压缩:使用不同的压缩算法对倒排索引进行压缩,以减少存储空间占用和提高读写效率。
- 预存储结果:插入数据时,预处理数据,将结果预存储于索引中,查询时无需重新计算,提升查询速度。
- 内存存储:应用内存映射(Memory Mapped)技术来提高磁盘I/O性能。它将倒排索引缓存在内存中,同时使用内存映射技术将文件映射到虚拟地址空间中。减少磁盘访问次数,提高数据存储与查询效率。
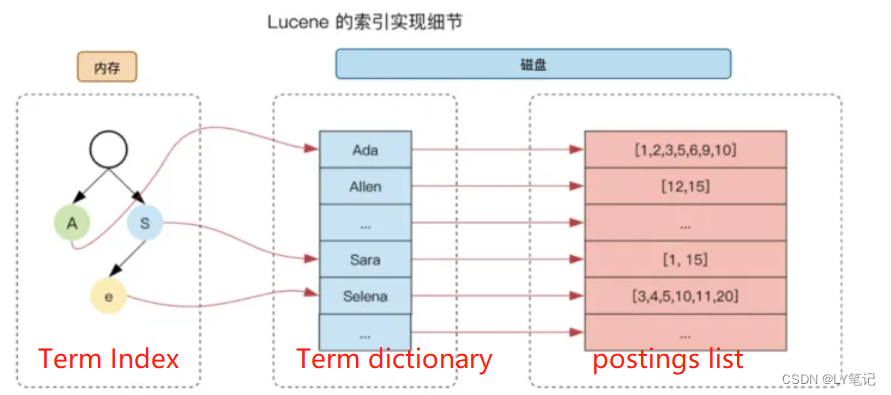
Term Index: 倒排的树状结构,存在内存里,是Term dictionary的索引。
基本概念:
- Cluster,集群。一个集群包含多个节点,对外提供服务。
- Node,节点。一个节点运行在一个独立的环境或虚拟机上,一个节点可以包含多个分片,一个索引由多个分片组成
- Shard,分片。(Primary Shard 和 Replica Shard),主分片数量在创建索引的时候就需要固定,并且无法做修改。
- Index,索引,相当于mysql中的库。
- Type,类型,一个索引可以对应一个或者多个类型。(ES6.0后被废弃,ES7完全删除)
- Mapping,映射,相当于表结构。
- Document,文档,相当于行。
- Field,字段,相当于列。
分片与副本的区别在于:
- 当分片设置为5,数据量为30G时,ES会将数据平均分配到5个分片上,每个分片6G数据。进行数据查询时,ES会把查询发送给每个分片,最后将结果组合在一起。目的是保障查询的高效性。
- 副本是对分片的数据进行复制,目的是保障数据的高可靠性,防止丢失。
Filter VS Query
尽可能使用过滤器上下文(Filter)替代查询上下文(Query)
- Query:此文档与此查询子句的匹配程度如何?
- Filter:此文档和查询子句匹配吗?
Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一样计算相关性分数,同时Filter结果可以缓存。
Reindex 重建索引的原理:
Scroll Query + Bulk
Ingest pipeline 可以在数据存入ES之前对数据进行转换,例如转小写,增加字段等。
性能优化:
背景:每五分钟就有6.5M条数据,直接reindex需要1000s(15分钟)
- 创建索引前设置主分片数量为二,副本比例为一,700s
- batch size = 2000(原来为默认值1000,使用堆缓存索引数据,默认最大值为100 MB), 副本比例为零,480s,平均每个 document 30-40 kb 左右
- slice = 2(其实是三个并行任务,一个父任务二个子任务),420s(甚至有一次350s)
text 和 keyword 的区别
text类型: text类型是指可分词的文本,适用于长文本或短语查询。当文本被索引时,会被分成一些个别单词或词组,并且会去除停用词(如“a”、“the”、“and”等)和标点符号。这些单词或词组将被标准化并存储在倒排索引中,使得搜索时可以更快地匹配文档。适合全文搜索。
keyword类型: keyword类型是指未经过分词处理的文本,适用于精确匹配和排序。当文本被索引时,会被作为一个整体进行索引。它们通常用于搜索和排序非文本字段,例如数字或日期。适合过滤、排序、聚合。
ElasticSearch 默认为text类型,但是text类型总会有keyword的类型的字段,等价于 .keyword
ES 调优
硬件配置优化
- CPU 配置
- 内存配置
- 禁止 swap
- 配置 GC
- 磁盘
索引优化
- 批量提交(Bulk),但不能一次性提交过多内容。
- 增加 refresh 时间间隔
- 减少副本数量
查询优化
- 尽可能使用过滤器上下文(Filter)替代查询上下文(Query)
- 拆分索引
- 减少模糊匹配
数据结构优化
- 减少不需要的字段
- text 和 keyword 类型字段的设置
集群架构设计
- 设置分片数量,但不宜过大。
扩容
垂直扩容(纵向扩容):替换旧的设备
水平扩容(横向扩容):直接新增设备到集群中,会触发relocation
写入和更新的并发

针对写入和更新时可能出现的并发问题,ES是通过文档版本号来解决的。当用户对文档进行操作时,并不需要对文档加锁和解锁操作,只需要带着版本号。当版本号冲突的时候,ES会提示冲突并抛出异常,并进行重试
存储结构

- 一个集群包含1个或多个节点;
- 一个节点包含1个或多个索引;
- 一个索引,类似 Mysql 中的数据库;
- 每个索引又由一个或多个分片组成;
- 每个分片都是一个 Lucene 索引实例,您可以将其视作一个独立的搜索引擎,它能够对 Elasticsearch 集群中的数据子集进行索引并处理相关查询;
- 每个分片包含多个segment(段),每一个segment都是一个倒排索引。
查询时,会把所有的segment查询结果汇总归并为最终的分片查询结果返回。
段
段是不可变的
为了实现高索引速度,故使用了segment 分段架构存储。
一批写入数据保存在一个段中,其中每个段是磁盘中的单个文件。
由于两次写入之间的文件操作非常繁重,因此将一个段设为不可变的,以便所有后续写入都转到New段。
段合并
可以是内存里的段,也可以是在磁盘里的段进行段合并
流程
- 合并候选阶段:es会选择一些相似大小的段作为合并候选,减少合并过程中的IO开销。
- 合并阶段:ES将合并时候选中的多个段合并成为一个新的段,同时删除旧的段(在
.del文件里标记为删除)。在合并过程中ES会进行数据的排序和去重,并重新生成倒排索引
为什么要段合并
由于自动刷新流程每秒会创建一个新的段(由动态配置参数:refresh_interval 决定),这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦,导致:
- 消耗资源:每一个段都会消耗文件句柄、内存和cpu运行周期;
- 搜索变慢:每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
触发条件
后台进程定期检查,可能进行 merge 操作
- 手动触发
- 段 flush 触发
- 由前一个成功的 merge 触发
分词器
- ik-analyzer 分词器,支持中文分词
- pinyin 分词器,支持输入拼音查到相关关键词
- pattern 分词器,支持正则表达式
- whitespace 分词器,用于去除空格